分析Druid 连接池中SQL语法树的基本原理
分析Druid 连接池中SQL语法树的基本原理
作者:吴培能
Druid是数据库连接池,能够提供强大的监控和扩展功能。SQL Parser是Druid的一个重要组成部分,Druid内置使用SQL Parser来实现防御SQL注入(WallFilter)、合并统计没有参数化的SQL(StatFilter的mergeSql)、SQL格式化、分库分表。Druid SQL Parser分三个模块:Parser,AST,Visitor。parser是将输入文本转换为ast(抽象语法树),parser有包括两个部分,Parser和Lexer,其中Lexer实现词法分析,Parser实现语法分析,AST是Abstract Syntax Tree的缩写,也就是抽象语法树。Visitor是遍历AST的手段,是处理AST最方便的模式。
使用场景
在数据服务平台中的主要使用场景
1、sql语法有效性校验
2、sql中指定字段提取(例如:列名,表名,条件)
感性认识抽象语法树
语法树生成流程
使用antlr4 生成 SELECT A.ID B.ID FROM A LEFT JOIN B ON A.ID =B.ID LEFT JOIN C ON B.ID = C.ID 的抽象语法树。具体的节点内容的名称和语法的规则名称有关,但是叶子节点的内容就是我们手写的语句内容,除了关键字。
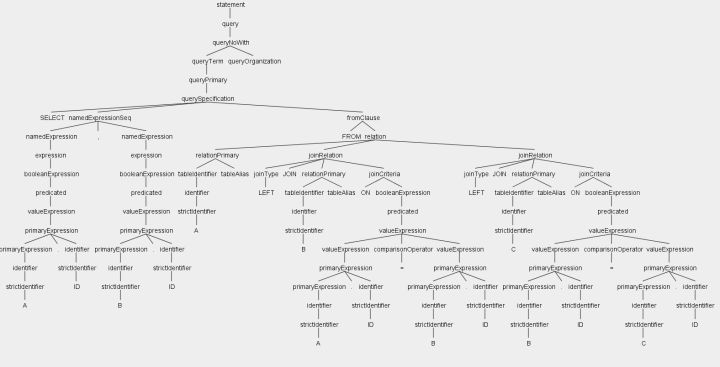

生成语法树一般过程:字符流->词法解析器->token流->语法解析器->语法树。
对于字符流经过词法解析器后变成token流,如 SELECT A.ID,B.ID FROM A 将变成如下的token流。
| SELECT |
| FROM |
接下来语法解析器根据上面的token流生成一棵语法树
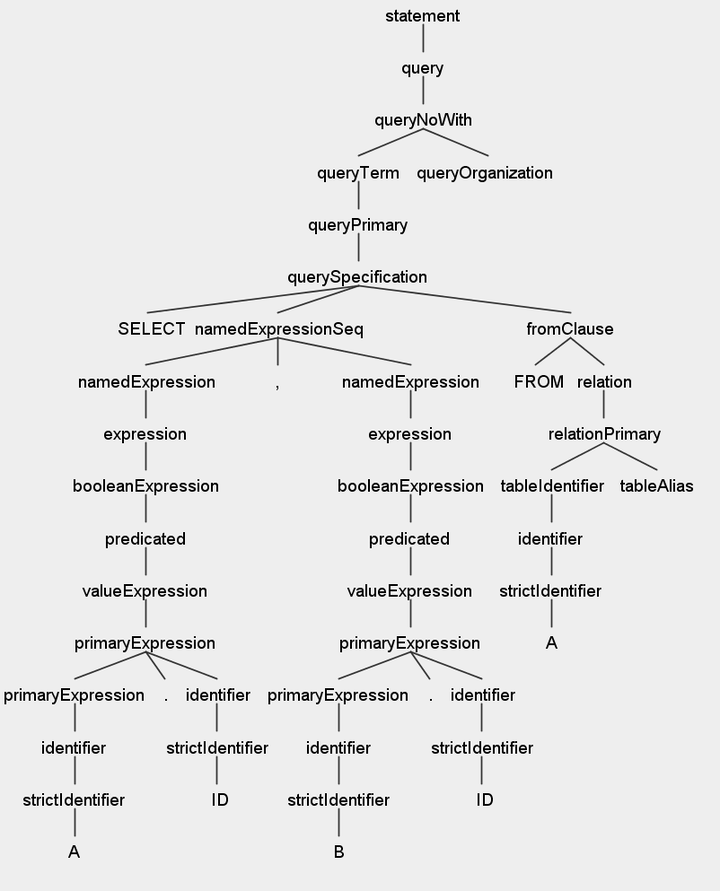

使用SQL Parser生成一棵抽象语法树
maven依赖
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>版本号</version> </dependency>
java代码
public class SqlParse { public static void main(String[] args) { String sqlStr = "SELECT A.ID,B.ID FROM A LEFT JOIN B ON A.ID =B.ID LEFT JOIN C ON B.ID = C.ID"; //支持的数据库类型在DbType中的枚举值 SQLStatement stmt = SQLUtils.parseSingleStatement(sqlStr, DbType.mysql); } }
Druid Parser原理分析
SQLUtils.parseSingleStatement(sqlStr, DbType.mysql) 会调用SQLParserUtils.createSQLStatementParser(sql, dbType, features)获取到一个 SQLStatementParser的子类,如果是mysql,那么返回的类就是MySqlStatementParser。
SQLStatement stmt = SQLUtils.parseSingleStatement(sqlStr, DbType.mysql); public static SQLStatement parseSingleStatement(String sql, DbType dbType, SQLParserFeature... features) { SQLStatementParser parser = SQLParserUtils.createSQLStatementParser(sql, dbType, features); List<SQLStatement> stmtList = parser.parseStatementList(); if (stmtList.size() > 1) { throw new ParserException("multi-statement be found."); } if (parser.getLexer().token() != Token.EOF) { throw new ParserException("syntax error. " + sql); } return stmtList.get(0); } public static SQLStatementParser createSQLStatementParser(String sql, DbType dbType, SQLParserFeature... features) { if (dbType == null) { dbType = DbType.other; } switch (dbType) { case oracle: case oceanbase_oracle: return new OracleStatementParser(sql, features); case mysql: case mariadb: case drds: { return new MySqlStatementParser(sql, features); } ..... } }
按照生成语法树一般过程 字符流->词法解析器->token流->语法解析器->语法树 的过程,其中sqlStr就是字符流。那么接下来应该就是词法解析器,但是SQLUtils.parseSingleStatement(sqlStr, DbType.mysql)直接就返回一棵AST树,其实在SQLUtils.parseSingleStatement(sqlStr, DbType.mysql),做了很多操作。
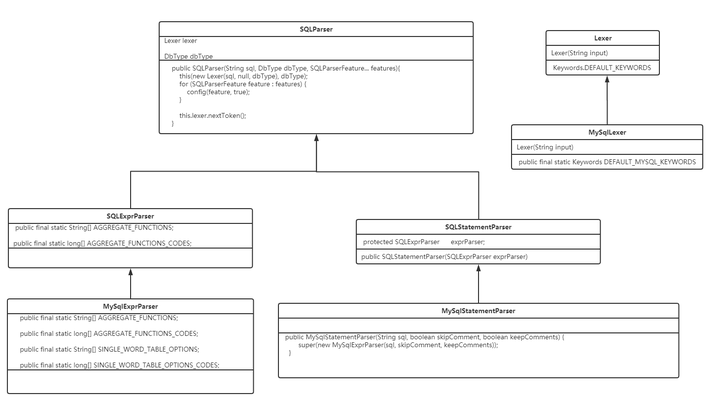

在实例化一个 MySqlStatementParser的时候,会实例化 MySqlExprParser,然后再实例化 MySqlLexer。
本质来说,Lexer,SQLParser,SQLExprParser,SQLStatementParser是基类,定义了所有数据库类型都会用到的基本信息,
Lexer是词法解析器,保存原始的字符流和关键字,对字符流进行词法分析。MySqlLexer则是继承Lexer,并在Lexer原有的关键字基础上添加自己的特有的关键字。
SQLExprParser定义了聚合函数,但是MySqlExprParser并不在在原来的基础上添加,而是直接重写。
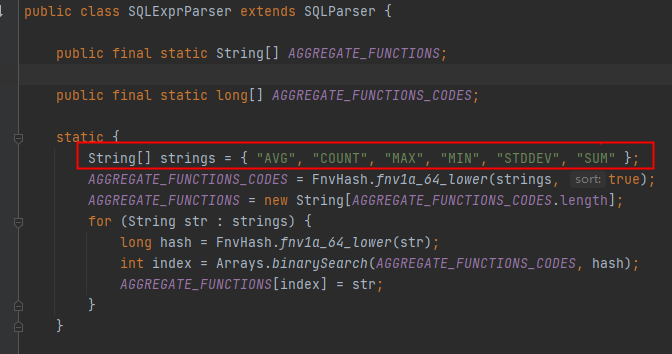

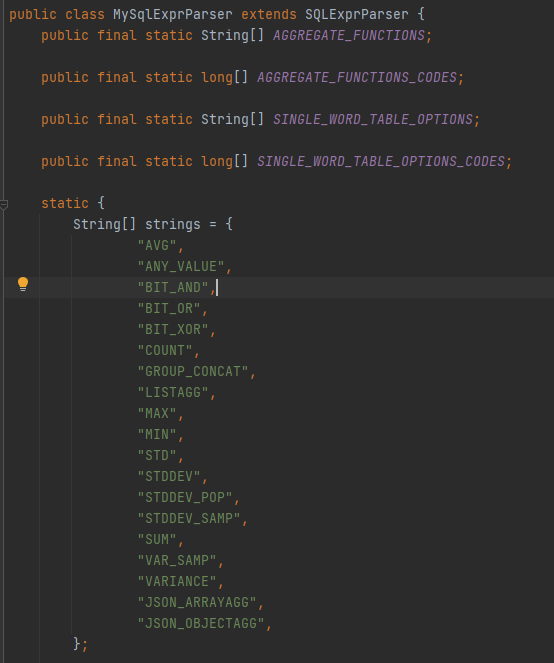

在生成MySqlStatementParser后,调用parseStatementList()方法,进行语法解析.druid的解析规则是自己手写的,在性能上优于使用antlr4,一是语法规则上的优化,二是解析过程中的差异。
使用antlr4进行解析的时候,是先将所有的字符流变成token流后,再解析生成语法树,但是druid是边解析字符流,边解析生成语法树,这样如果有语法问题的话,那么就直接报错,而不用解析完字符流。
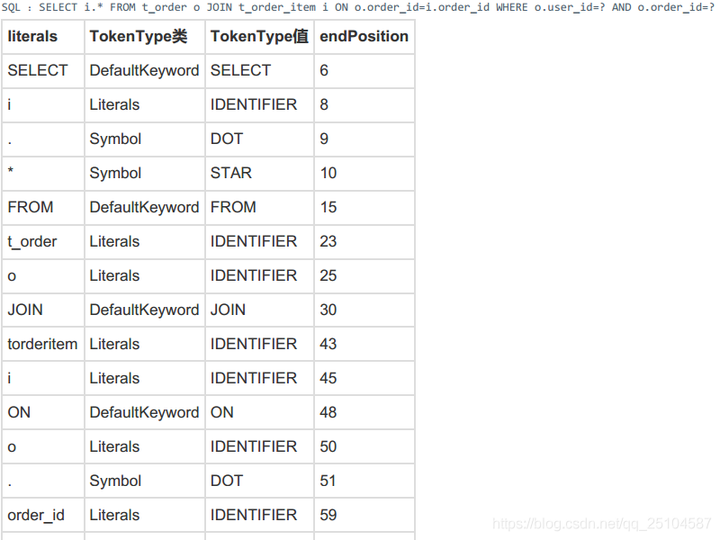

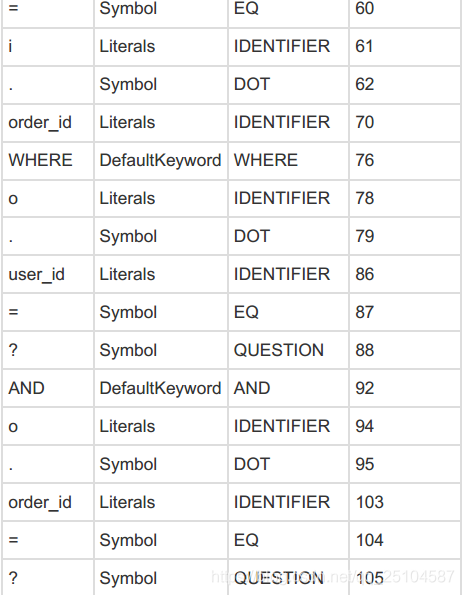

首先读取select后,变成一个token,然后语法分析器遇到select,匹配select语法。然后再下一步读取字符生成token.如果第一步读取的字符不符合语法规则,则直接进行报错。
Druid Visitor原理分析
在Druid中,AST节点类型主要包括SQLObject、SQLExpr、SQLStatement三种抽象类型。
所有的AST节点都支持Visitor模式,需要自定义遍历逻辑,可以实现相应的ASTVisitorAdapter派生类。
public class TableVisitor extends MySqlASTVisitorAdapter { private List<String> tableNames= new ArrayList<>(); public boolean visit(SQLExprTableSource sqlExprTableSource) { String taleName = sqlExprTableSource.getTableName(); tableNames.add(taleName); return true; } public List<String> getTableNames() { return tableNames; } } #获取sql语句中的表 public static void main(String[] args) { String sqlStr = "SELECT A.ID,B.ID FROM A LEFT JOIN B ON A.ID =B.ID LEFT JOIN C ON B.ID = C.ID"; SQLStatement stmt = SQLUtils.parseSingleStatement(sqlStr, DbType.mysql); TableVisitor tableVisitor = new TableVisitor(); stmt.accept(tableVisitor); System.out.println(tableVisitor.getTableNames()); }
结果:




stmt.accept(tableVisitor) 使用深度优先算法遍历所有的语法节点,如果遇到SQLExprTableSource节点,则会调用TableVisitor的 visit(SQLExprTableSource sqlExprTableSource)方法。
如果想要获取指定节点的内容,那么就重写visit(节点类型)方法,并在方法体里面实现自己的逻辑即可。
想要知道支持哪些节点类型,直接看DbTypeASTVistitorAdapter里面的方法以及对应的父类里面的所有的visit方法里面的类型,其中DbType是指数据库类型,比如mysql,oracle,hive等。


更多精彩,请关注公众号DEEPEXI滴普科技